

基于大数据与模式识别技术对中药材品质的快速评价研究
时间:2023-03-08人气:作者: 百草药源
来源:《天然产物研究与开发》2023
基于大数据与模式识别技术对中药材品质的快速评价研究
张立军 张新玥 马冬妮 张转平 谭艳萍 钟海婷 熊贤锋 刘丽
陕西省安康市食品药品检验检测中心 北京中医药大学中药学院 甘肃省敦煌市医院
中药是中医药大健康产业的主体,中药质量关系大健康产业的发展。目前中药质量仍存在品种多、差异大、追溯过程长、检测指标繁琐及缺乏科学评价方法等问题。此外,在中药质量监管过程中产生和积累的海量原始数据,并没有从数据中发现规律、有效利用率低,存在数据丰富(data rich)、知识匮乏(knowledge poor)的问题。在国务院2015年发布《促进大数据发展行动纲要》推动下,借助大数据融合、云计算及区块链等现代信息技术应用于中药产业科学监管成为未来的必然发展趋势。中药产业大数据中隐含的模式和规则往往无法靠经验或直觉发现,需要借鉴大数据分析的思维和方法将药材的生长环境、种植加工、炮制、化学成分演变及传统质量控制等低质、碎片化的数据转变成高质、高价值密度信息,然后借助数据挖掘、机器学习、人工智能等计算方法,并结合中药专业知识和判断,建立与应用相关联的数学模型,将实体关系透明化,为中药材品质的科学监管提供重要依据。
随着化学计量学的快速发展与应用,针对食品药品安全检测仪器和技术得到了迅速发展。检测方法也由早期的理化(physicochemical)、显微(microscopical)、色谱(chromatography)及质谱(mass spectrometry,MS)等技术,发展到非接触的近红外光谱(near infrared spectroscopy,NIRS)、拉曼(raman spectrometry,RS)、太赫兹(tera hertz,THz)及高光谱成像(hyperspectral imaging,HI)等技术。其中NIRS是近几年发展起来的,是以采集被检测物质含氢基团X-H(X=C、N、O)在近红外谱区振动、转动的合频及倍频信息用于物质定性和定量分析,广泛应用于农业、石油、化工、烟草及食品中,目前已被逐步应用于制药及药监行业,在药品快速定性和定量检测分析方面具有很大的发展潜力。
柴胡Bupleuri Radix为伞形科植物柴胡Bupleurum chinense DC.或狭叶柴胡B. scorzonerifolium Willd.的干燥根,是我国常用的大宗药材,始载于《神农本草经》,列为上品,具有和解退热、疏肝解郁、升举阳气的功效,前者习称“北柴胡”,后者习称“南柴胡”。北柴胡主产于河北省、黑龙江省、辽宁省等,南柴胡主产于辽宁省、吉林省、内蒙古自治区等。因柴胡原植物品种复杂,本属约有100余生物种,我国有36个生物种、17个变种及7个变型,此外生长环境变迁、品种变异、加工炮制及非药用部位去除不净等,药材品质差异很大。目前《中国药典》2015、2020年版对其水分、灰分、酸不溶性灰分、浸出物、柴胡皂苷a和d等含量进行了限定,对柴胡质量控制发挥了重要作用。然而质量标志物(Q-marker)研究发现,柴胡中挥发油及脂肪油、三萜皂苷及黄酮类成分是其解热镇静、镇痛抗炎及镇咳的主要活性成分。目前对于柴胡质量评价虽然多项指标并存,但含测指标单一、限量过低,不能满足对其品质评价与等级划分的需求。此外,监管过程中产生和积累了大量碎片化原始数据未得到充分利用、缺乏系统的整合。故本研究基于大数据背景下,以北柴胡药材为例,收集本中心采用《中国药典》2015年版检测的130批次北柴胡药材各项检测数据,采用NIRS分析技术、化学计量法及数学建模方法对北柴胡药材各项检测数据进行模式识别研究,建立北柴胡药材快速溯源分析模型、含量预测模型、药材品质综合评价与等级划分数据库,系统地评价北柴胡药材品质,为中药材品质的科学监管提供新思路。
1 材料与方法
1.1 仪器
傅里叶变换Tensor 37 NIRS仪,OPUS 5.0分析软件(德国Bruker公司);LC-20AT高效液相色谱仪,LC Solution色谱工作站(日本岛津公司);Phenomenex ODS C18色谱柱(250 mm × 4.6 mm,5 μm);BS224S电子分析天平;FW-400A高建万能粉碎机(北京科伟永兴仪器有限公司)。
1.2 试药
收集本中心2015年—2020年抽检样品中采用《中国药典》2015年版检测的130批次北柴胡(BCD)药材,包括北柴胡及其炮制品、不合格品,均为全检;柴胡皂苷a(批号110777-201912,纯度94.8%)、柴胡皂苷d(批号110778-201912,纯度96.3%)均购于中国食品药品鉴定研究院;乙腈和甲醇均为色谱纯;氨水、乙醇均为分析纯。
1.3 收集北柴胡药材6项指标的检测数据
收集本中心2015年—2020年抽检样品中采用《中国药典》2015年版检测的130批次北柴胡药材6项指标检测数据,包括水分、灰分、酸不溶性灰分、浸出物、柴胡皂苷a和d的总量及茎秆占比(中心内部规定茎秆占比不得超过10%)。
1.4 NIRS采集与预处理
取训练集北柴胡药材粉末(过6号筛),置于石英杯中(直径2 cm),装量为石英杯体积的三分之二,振摇混匀。以空石英杯为空白参照,采用积分球漫反射测样,扫描波段范围12 000~4 000 cm–1,扫描时间64 s,分辨率16 cm–1,温度10~30 ℃,湿度35%±5%。为了提高准确度,每个样品重复测定5次求平均光谱用于建模分析。研究采用NIRS仪自带的OPUS软件对每个样品光谱进行预处理。
1.5 北柴胡药材溯源分析模型建立与应用
为了实现对不同产区北柴胡药材溯源分析,以识别率为指标,采用“1.4”项预处理方法优化光谱数据;根据方差光谱选取方差较大的波段作为特征波段,结合SIMCA 14.1统计软件中(principal components analysis,PCA)和(partial least square discriminant analysis,PLS-DA)分析进行建模,并对构建模型进行验证。
1.6 北柴胡药材多指标定量分析模型建立及应用
采用“1.4”项光谱预处理方法,以决定系数(correlation coefficient,R2)、训练集均方根误差(root mean square error of cross-validation,RMSECV)、验证集均方根误差(root mean square error of prediction,RMSEP)以及相对分析误差(relative analysis error,PRD)为评价指标确定最佳光谱预处理方法。通过PLS-DA,采用各自最佳光谱预处理方法、光谱区域及主因子数建立定量分析模型,并对构建模型进行验证。
1.7 北柴胡药材品质综合评价模型的建立与应用
1.7.1 原始数据无量纲化处理
由于样品各检测指标间的单位与量纲不同,及考虑检测指标与药材品质正负相关性,为体现样品的差异性和方便计算,采用最大优越型(Rij)和最小优越型(R’ij)分别对各指标原始数据进行同度无量纲化处理,计算公式如下:
Rij=Xij/maxXij;R’ij=minXij/Xij
式中,Xij指第j个样品的第i项指标的测定结果;maxXij指在m个样品中第i项正相关指标的含量最大值;minXij指在m个样品中第i项负相关指标的含量最小值(1≤i≤n;1≤j≤m)。
1.7.2 指标权重系数计算
采用变异系数计算Wi,计算过程如下:

式中,Wi指第i项指标的权重系数;δi指第i项指标的变异系数;
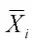 指第i项指标的平均值;Di指第i项指标的均方差。
指第i项指标的平均值;Di指第i项指标的均方差。
1.7.3 综合评价指数计算
综合评价指数(Fq)是反应样品与标准样品间相互接近的程度,其值越大越接近。根据Fq大小来综合评价样品的品质和等级划分。同时基于各检测指标对药材品质贡献度的不同,赋予不同的权重系数Wi,建立体现药材整体质量的综合评价数学模型:
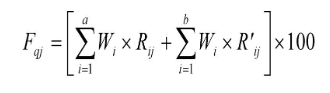
式中,Fqj指第j个样品的综合评价指数得分;a指正相关指标的个数,b指负相关指标的个数。
2 结果与分析
2.1 训练集、验证集与预测集样品选取
采用Kennard-Stone方法将样品划分为训练集和验证集,研究中选用90批作为训练集,20批为验证集用于建模研究,剩余的作为预测集。训练集和验证集样品6项指标的含量分布见表1。
表1 训练集和验证集北柴胡样品6项指标的含量分布
检测指标 Detection index | 训练集 Calibration set(n=90) | 验证集 Validation set(n=20) | ||
质量分数 Content(%) | 平均值 Mean(%) | 质量分数 Content(%) | 平均值 Mean(%) | |
水分 Water | 4.0~13.3 | 7.7±1.86 | 5.9~10.9 | 7.9±1.38 |
灰分 Total ash | 3.8~11.3 | 6.0±1.56 | 3.9~8.9 | 5.4±1.02 |
酸不溶性灰分Acid-insoluble ash | 0.9~5.1 | 1.8±0.81 | 0.9~3.9 | 1.7±0.66 |
浸出物 Extract | 10.8~21.5 | 14.8±2.96 | 11.5~20.9 | 15.7±2.79 |
柴胡皂苷a+d Saikosaponins a and d | 0.33~1.93 | 0.92±0.34 | 0.56~1.92 | 1.01±0.26 |
茎秆占比 Proportion of stem | 0.5~10.7 | 4.7±2.2 | 0.5~9.6 | 4.6±2.1 |
注:平均值采用均数±标准差表示。Note: Mean is expressed as`x ± s.
2.2 NIRS采集与预处理
采用“1.4”项方法采集每个样品光谱。因采集NIRS时,存在随机噪声、基线漂移、光散射、样本颗粒大小等随机因素的影响,导致光谱的差异,干扰NIRS与样本目标成分含量的关系,影响建模型的可靠性和稳定性。研究分别采用消除常数偏移(elimination of constant offset,ECO)、多散射校正(multiplication signal correction,MSC)、标准正态变换(standard normal variate,SNV)、一阶导数(first derivative,FD)、二阶导数(second derivative,SD)及平滑(smoothing points,SP)等组合方法处理光谱中存在的无用信息,以期提高模型判别的准确度,见图1。
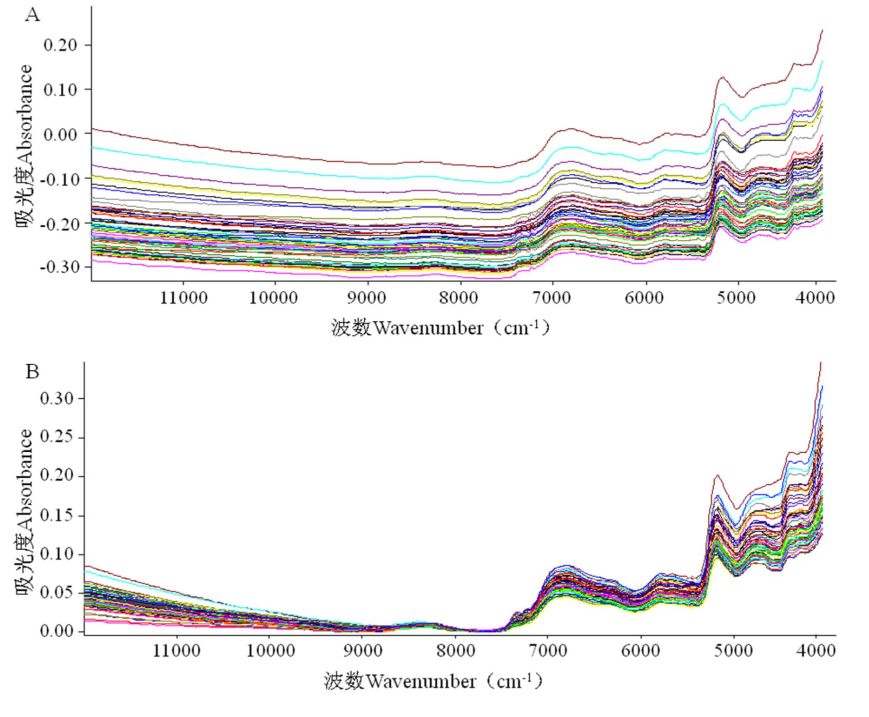
图1 训练集中60批次北柴胡样品的近红外光谱图
注:A-原始光谱;B-消除常数偏移+标准正态转换。Note: A-Raw spectrum; B-ECO + SNV.
2.3 北柴胡药材溯源分析模型建立与应用
2.3.1 模型建立
PCA分析模型识别率结果见表2,特征波段见图2A。由表2和图2A可知,采用最优预处理方法ECO+SNV+SP处理光谱、根据方差光谱选取方差较大的波段(4 204.15~5 608.51 cm–1、6 325.51~7 606.04 cm–1、7 612.50~8 101.00 cm–1、8 120.10~9 609.66 cm–1)作为特征波段结合PCA分析,基本可以实现5个产区北柴胡药材的产区划分,但效果不佳,陕西省、河北省与四川省均有部分重叠,见图2B。
表 2 通过SIMCA和不同的预处理方法获得的识别率
预处理方法 Pretreatment method | 识别率 Identification accuracy(%) | |||||
陕西省Shanxi | 河北省Hebei | 辽宁省Liaoning | 四川省Sichuan | 内蒙古自治区 Inner Mongolia | 整体Overall | |
ECO+SNV+SP | 70 | 80 | 90 | 100 | 90 | 86 |
ECO+SNV+FD | 60 | 70 | 70 | 100 | 80 | 76 |
ECO+SNV | 60 | 50 | 70 | 90 | 80 | 70 |
ECO | 40 | 60 | 70 | 90 | 80 | 68 |
SNV | 50 | 70 | 80 | 100 | 70 | 74 |
MSC | 40 | 50 | 70 | 80 | 90 | 66 |
SD | 40 | 80 | 70 | 80 | 60 | 66 |
FD | 50 | 70 | 80 | 90 | 80 | 74 |
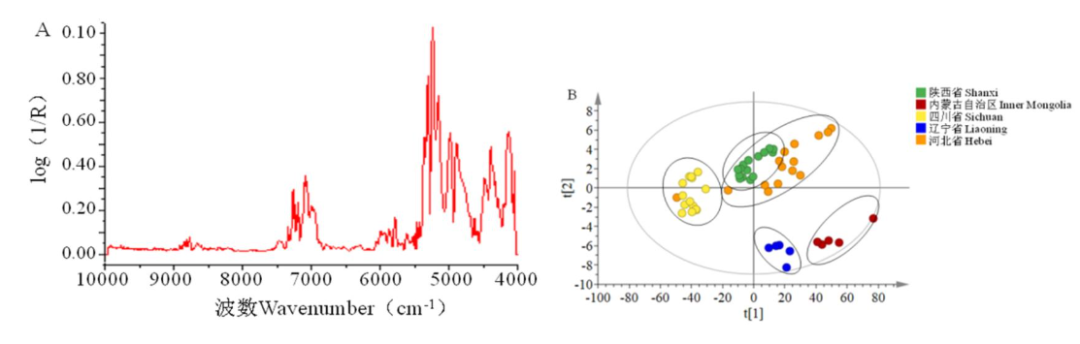
图2 北柴胡药材PCA模式识别模型的方差光谱图(A)及得分图(B)
为进一步提高识别准确率,在PCA分析基础上,按照主成分贡献率大于1%,累计贡献率大于75%的原则选择3个主成分,见表3。采用PLS-DA分析进行建模,结果5个产区北柴胡药材被较好地分开,PLS-DA得分图见图3A。对得分图进行分析,该模型自变量累计解释能力R2X为0.983,因变量累计解释能力R2Y、Q2Y分别为0.901、0.820,均大于0.5,且0<R2Y-Q2Y=0.081<0.3。R2与Q2与纵轴和横轴交点均小于0.5,表明建立模型没有出现过度拟合,见图3B,说明模型预测能力较好。对波段变量的重要性投影(VIP)值进行排序,VIP值越大,说明该波段对产地区分的贡献越大。因此,该法选择波段并不连续,由许多波段累计组合,主要特征波段为4 104.35~5 708.00 cm–1、6 101.51~7 382.33 cm–1、7 768.95~8 701.25 cm–1及8 120.10~9 609.66 cm–1。特征波段的区间与PCA特征波段区间基本一致。NIRS分析显示,上述波段是表征挥发油、皂苷及黄酮类物质中O-H、C=O、C-H键振动的主要区间,继而反映出北柴胡药材所含化学成分的差异。
表3 主成分及贡献率
主成分数 Principal component | 特征值 Eigenvalue | 贡献率 Contribution rate(%) | 累计贡献率 Cumulative contribution rate(%) |
1 | 28.7 | 95.070 | 95.070 |
2 | 15.6 | 2.195 | 97.265 |
3 | 2.05 | 1.047 | 98.312 |

图3 北柴胡药材PLS-DA模式识别模型的得分图(A)与模型检验图(B)
2.3.2 模型的验证与应用
为了验证PLS-DA模型的可靠性,分别将验证集和预测集样品的NIRS输入溯源模型中进行内、外部验证。结果内部验证识别率均为100%,外部验证5个产区样品中除了陕西省和河北省识别率为90%,其余3个产区识别率均为100%,整体识别率为90%(见表4)。
表4 北柴胡样品产地预测结果
项目 Project | 验证集 Validation set | 预测集 Predicted set | ||||||||
陕西省 Shaanxi | 河北省 Hebei | 辽宁省 Liaoning | 四川省 Sichuan | 内蒙古自治区 Inner Mongolia | 陕西省 Shaanxi | 河北省 Hebei | 辽宁省 Liaoning | 四川省 Sichuan | 内蒙古自治区 Inner Mongolia | |
样品个数 Sample size | 6 | 3 | 5 | 4 | 2 | 5 | 5 | 4 | 4 | 2 |
预测准确个数Predicted size | 6 | 3 | 5 | 4 | 2 | 4 | 4 | 4 | 4 | 2 |
2.4 北柴胡药材多指标定量分析模型建立及应用
2.4.1 模型建立
结果分别得到北柴胡药材6项指标的NIRS定量分析模型,其水分、灰分、酸不溶性灰分、浸出物、柴胡皂苷a与d总量及茎秆占比的Rcal2分别为0.982、0.934、0.942、0.915、0.938及0.955,均大于0.85;RMSECV分别为0.151、0.215、0.156、0.123、0.210及0.175,均为各自模型的最小值,说明模型预测性能良好,见表5。
表5 不同预处理方法以及光谱区段对定量分析模型的影响
检测指标 Detection index | 预处理方法 Pretreatment method | 谱区选择 Select band(cm–1) | 主因子数 Factor number | R2cal | RMSECV | RPD |
水分 Water | FD+SNV | 7 501.9~5 450.6;4 601.0~4 414.0 | 7 | 0.982 | 0.151 | 5.120 |
FD+SNV | 5 152.7~4 415.0 | 5 | 0.816 | 0.211 | 3.860 | |
SNV | 7 501.9~4 420.0 | 6 | 0.756 | 0.251 | 2.670 | |
灰分 Total ash | SD+SNV | 7 501.7~5 350.6;4 701.0~4 404.0 | 10 | 0.934 | 0.215 | 5.630 |
SD+SNV | 5 453.8~4 597.6 | 7 | 0.865 | 0.235 | 4.910 | |
SD | 6 230.8~4 120.0 | 5 | 0.815 | 0.242 | 2.910 | |
酸不溶性灰分 Acid-insoluble ash | SD+MSC | 8 100.1~5 751.0;4 623.0~4 210.0 | 7 | 0.942 | 0.156 | 5.310 |
SD+MSC | 5 453.8~4 597.6 | 6 | 0.915 | 0.220 | 4.420 | |
SD | 6 230.8~4 120.0 | 6 | 0.822 | 0.352 | 3.110 | |
浸出物 Extract | SNV | 7 929.0~5 325.0;4 512.1~4 221.0 | 8 | 0.915 | 0.123 | 4.740 |
SNV | 5 325.0~4 213.0 | 8 | 0.856 | 0.176 | 4.012 | |
FD | 7 956.0~4 327.0 | 7 | 0.830 | 0.182 | 3.202 | |
柴胡皂苷a+d Saikosaponins a and d | FD+MSC | 8 123.0~5 522.2;4 912.0~4 324.5 | 7 | 0.938 | 0.210 | 4.370 |
SNV | 5 925.0~4 280.0 | 8 | 0.852 | 0.226 | 2.120 | |
FD | 7 986.0~4 314.0 | 6 | 0.831 | 0.280 | 2.203 | |
茎秆占比Proportion of stem | FD+SNV | 7 511.2~5 444.2;4 810.3~4 656.1 | 6 | 0.955 | 0.175 | 4.450 |
SNV | 5 656.0~4 251.0 | 7 | 0.877 | 0.179 | 3.813 | |
FD | 7 875.0~4 221.0 | 7 | 0.811 | 0.189 | 3.116 |
2.4.2 模型的验证与应用
将验证集样品的NIRS输入到上述模型中,预测样品各项检测指标的含量,结果6项指标的预测值和实测值的Rtest2分别为0.958、0.928、0.951、0.947、0.901及0.956,表明所建立的模型具有很好的预测能力,见图4。
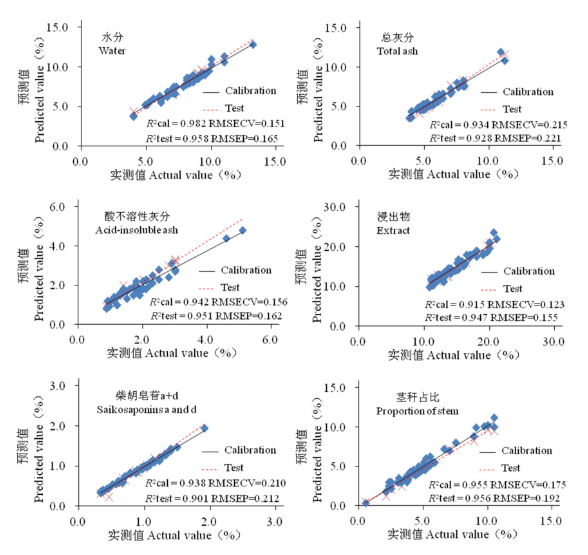
图4 北柴胡药材6项检测指标的NIRS检测模型
利用上述所建立的模型,对预测集20批北柴胡样品进行6项检测指标快速分析,并建立快速评价数据库。含量预测结果显示,不符合《中国药典》规定的样品为4批,主要集中在水分、总灰分、酸不溶性灰分、浸出物及茎秆占比(中心内部规定茎秆占比不得超过10%)项下,见图5。
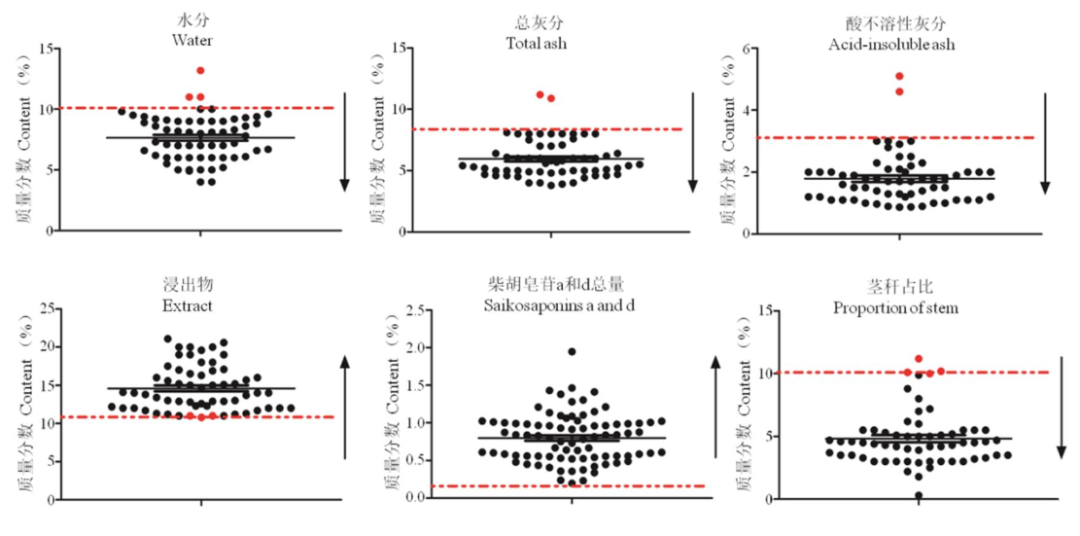
图5 北柴胡样品6项检测指标的近红外检测值
注:黑点表示合格样品,红点表示不合格样品;黑色实线为检测均值与误差棒,红色虚线为检测限量;箭头方向代表满足限量要求的合格样品趋势。
2.5 北柴胡药材品质综合评价模型的建立与应用
2.5.1 北柴胡药材品质的综合评价与等级划分模型建立
分别将90批北柴胡样品的6项指标数据代入“1.7”项综合评价模型各计算公式中,得水分、灰分、酸不溶性灰分、浸出物、柴胡皂苷a和d总量及茎秆占比最佳权重系数W1、W2、W3、W4、W5、W6分别为0.112 3、0.121 1、0.207 3、0.092 1、0.155 3和0.203 0,该条件下Fq计算公式如下。
Fqj=[0.112 3×R1j+0.121 1×R2j+0.207 3×R3j+0.092 1×R4j+0.155 3×R5j+0.203 0×R6j] ×100
通过对90批北柴胡样品的Fq值计算,结果Fq值范围在25.55%~80.08%,且Fq值呈高斯分布(Sig=0.25),见图6A。依据正态分布区域的样品数与实际“辨状论质、理化检测”结果建立等级划分数据库。将其分为4个区域,Fq值<30%为不合格;Fq值在30%~50%为三等品;Fq值在50%~70%为二等品;Fq值在70%~100%为一等品,见图6B。

图6 北柴胡药材的综合品质评价与等级划分
注:A-90批北柴胡样品Fq值的散点分布;B-正态分布区域中不合格区域及等级划分。
2.5.2 等级划分模型的验证与应用
依据上述建立的等级划分数据库,对40批北柴胡药材NIRS定量模型预测数据进行分析。结果显示,不合格为4批、三等品为33批、二等品为3批。4批不合格样品按照《中国药典》2020年版一部检测,结果分别为茎秆占比(>10%)、浸出物(<11.0%)不合格;合格样品均分布在二等及三等品的区域,其中3批二等品Fq值分别为55.73%、51.50%、50.30%,通过检测各项指标均较优,与实际“辨状论质、理化检测”质量相符,表明该模型用于北柴胡药材等级划分具有一定的合理性,见图7。

图7 北柴胡药材等级划分数据库预测结果
3 讨论与结论
参照德国“工业4.0”,目前我国中药产业总体处于工业2.0水平,相对较为滞后。Sigma差距指产品性能与消费者期望之间的差距,在六西格玛管理法中(6 Sigma是一个目标),目前我国中药产业处于2.0~3.0 Sigma水平,产生上述差距的原因为产品难以追溯、过于依赖最终产品检验(Quality testing),缺乏过程理解。2018年至2020年,我国中药饮片抽检不合格率远高于中成药与化药。中药饮片质量是中药临床安全有效的基础,关系中药大健康产业的发展,开展新的中药监管方法研究,实现中药质量科学监管显得尤为重要。影响中药材质量因素较多,如品种、生境、采收、加工炮制、储藏等,具有一定复杂性,但又存在必然的内在联系。要实现科学监管,需要相应交叉学科技术、信息科学及大数据科学的整合应用。近年来,我国对中药质量控制做了大量工作,但仍不能满足日益提高的质量控制要求。对此,有研究提出中药质量标志物(Q-marker)的概念,为中药质量评价指明了方向。然而中药质量综合评价涉及多个Q-marker,并且不同Q-marker对中药质量的贡献度也不相同,缺乏科学的综合评价方法。本实验提出中药综合评价指数Fq的概念,结合现行《中国药典》的评价体系,基于大数据分析的结果,通过对各检测指标Rij数据无量纲化处理,运用变异系数法优化计算中药质量评价指标的权重系数Wi,避免专家赋权的主观偏好性,较为客观地反映了中药质量评价各指标的相对重要程度。建立了一种适合中药材品质综合评价和等级划分的快速科学评价方法,为中药材质量的科学监管提供了新的方法。
科学监管是药物安全性、有效性及质量可控性的保证,中药材质量科学监管不仅要结合传统的经验、现行的评价体系及先进的技术方法,也要引入现代的信息技术和统计方法,通过对大数据提取分析建立中药材品质综合评价方法和等级划分标准。模式识别技术具有“整体性”和“模糊性”的特点,是一种综合的、可量化的鉴别手段,是当前符合中药特色,能很好地反映中药真实性。Fq是一个发展的体系,随着大数据的不断积累及Q-marker的不断引入,该体系也会不断迭代和完善,可以更好地应用于中药质量的科学监管。
版权归属原始权利人,文中观点仅代表作者本人,不代表本平台立场。转载请标明来源。
转载仅为传播中医药基础知识,如果本文侵犯了您的权利,请及时联系我们,以便洽谈授权或及时删除!

标签:
【免责声明】
1.“高鹏说药材”致力于提供中药行业各类资讯信息,但不保证信息的合理性、准确性和完整性,且不对因信息的不合理、不准确或遗漏导致的任何损失或损害承担责任。
2.“高鹏说药材”部分文章信息来源于网络转载是出于传递更多信息之目的,并不意味着赞同其观点或证实其内容的真实性。如对内容有疑议,请及时与我平台联系。
3.“高鹏说药材”所有信息仅供参考,不做任何商业交易及或医疗服务的根据,如自行使用“高鹏说药材”内容发生偏差,我平台不承担任何责任,包括但不限于法律责任,赔偿责任。
4.“高鹏说药材”各类带“原创”标识的资讯,享有著作权及相关知识产权,未经本网站协议授权,任何媒体、网站、个人不得转载、链接或其他方式进行发布;经本网协议授权的转载或引用,必须注明“来源:高鹏说药材(www.gpsyc.com)”。违者本网站将依法追究法律责任。
5.本声明未涉及的问题参见国家有关法律法规,当本声明与国家法律法规冲突时,以国家法律法规为准。
最新文章

百花农品:真药材,平价卖,守护千年药香
在中药材电商市场蓬勃发展的当下,乱象丛生:染色虫草、硫磺枸杞...(1080 )人阅读时间:2025-02-27
破茧重生:民间中医的千年传承亟需政策松绑!
中医,作为中华文明的瑰宝,数千年来以“简、便、验、廉”的特点...(926 )人阅读时间:2025-02-25
理性看待民间中医的作用:传承与困境中的“高手在民间”
中医作为中华文明的瑰宝,其生命力不仅存在于现代医疗体系内,更...(894 )人阅读时间:2025-02-24
让真药材回归百姓家——守护中药生态,百花农品与您同行!
中药,是中国人代代相传的健康密码,承载着“治未病”的智慧与自...(1025 )人阅读时间:2025-02-21
 中药指在中医药理论指导下认识和使用的药物[1],中医药界在发...
中药指在中医药理论指导下认识和使用的药物[1],中医药界在发... 中药材大品种全产业链创新研究的模式构建孙晓波*,刘海涛(中国...
中药材大品种全产业链创新研究的模式构建孙晓波*,刘海涛(中国...
 中药材物流现存问题及解决措施关丰,方玉强,沈绍基(1.中国仓...
中药材物流现存问题及解决措施关丰,方玉强,沈绍基(1.中国仓...


